¿Puede la IA aprender como nosotros?

Los investigadores han desarrollado una forma nueva y más eficiente energéticamente para que los algoritmos de IA procesen datos
Lee. Habla. Recopila montañas de datos y recomienda decisiones empresariales. La inteligencia artificial de hoy en día puede parecer más humana que nunca. Sin embargo, la IA todavía tiene varias limitaciones críticas.
“Por impresionantes que sean ChatGPT y todas estas tecnologías actuales de IA, en términos de interactuar con el mundo físico, todavía son muy limitadas. Incluso en cosas que hacen, como resolver problemas matemáticos y escribir ensayos, necesitan miles de millones de ejemplos de entrenamiento antes de poder hacerlas bien," explica Kyle Daruwalla, becario de NeuroAI del Laboratorio Cold Spring Harbor (CSHL).
Daruwalla ha estado buscando nuevas formas no convencionales de diseñar IA que puedan superar estos obstáculos computacionales. Y podría haber encontrado una.
La clave estaba en mover los datos. Hoy en día, la mayor parte del consumo de energía de la informática moderna proviene de rebotar datos. En las redes neuronales artificiales, que están compuestas por miles de millones de conexiones, los datos pueden tener que recorrer una distancia muy larga. Entonces, para encontrar una solución, Daruwalla buscó inspiración en una de las máquinas más potentes y eficientes en términos energéticos que existen: el cerebro humano.
Pensar como un cerebro
Daruwalla diseñó una nueva forma para que los algoritmos de IA muevan y procesen los datos de manera mucho más eficiente, basado en cómo nuestro cerebro absorbe nueva información. El diseño permite que las "neuronas" individuales de la IA reciban retroalimentación y se ajusten sobre la marcha en lugar de esperar a que se actualice todo el circuito simultáneamente. De esta manera, los datos no tienen que viajar tan lejos y se procesan en tiempo real.
“En nuestro cerebro, nuestras conexiones están cambiando y ajustándose todo el tiempo,” dice Daruwalla. “No es como si pausáramos todo, nos ajustáramos y luego volviéramos a ser nosotros mismos.”
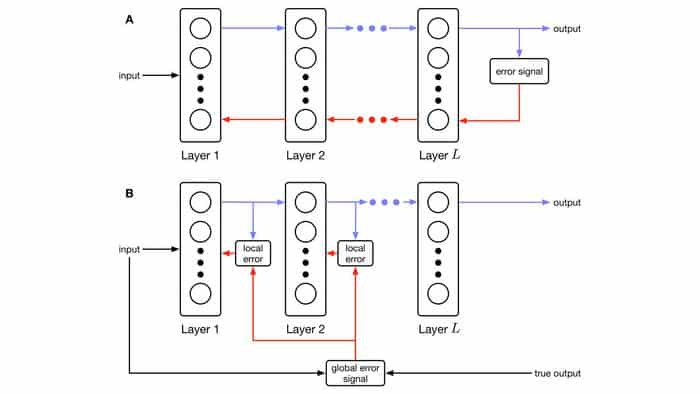
La imagen anterior muestra un esquema que compara los modelos típicos de aprendizaje automático (A) con el nuevo diseño de Daruwalla (B). La fila A muestra que la entrada o los datos tienen que viajar por todas las capas de la red neuronal antes de que el modelo de IA reciba retroalimentación, lo que requiere más tiempo y energía. En cambio, la fila B muestra el nuevo diseño que permite que la retroalimentación se genere e incorpore en cada capa de la red.
El nuevo modelo de aprendizaje automático proporciona evidencia de una teoría aún no probada que relaciona la memoria de trabajo con el aprendizaje y el rendimiento académico. La memoria de trabajo es el sistema cognitivo que nos permite mantenernos enfocados en una tarea mientras recordamos conocimientos y experiencias almacenados.
“Ha habido teorías en neurociencia sobre cómo los circuitos de la memoria de trabajo podrían ayudar a facilitar el aprendizaje. Pero no hay algo tan concreto como nuestra regla que realmente relacione estos dos. Y así fue una de las cosas agradables en las que tropezamos aquí. La teoría llevó a una regla donde ajustar cada sinapsis individualmente hacía necesaria esta memoria de trabajo junto a ella," dice Daruwalla.
El diseño de Daruwalla puede ayudar a abrir una nueva generación de IA que aprende como lo hacemos nosotros. Eso no solo haría que la IA sea más eficiente y accesible—también sería algo así como un momento de círculo completo para neuroAI. La neurociencia ha estado alimentando a la IA con datos valiosos mucho antes de que ChatGPT pronunciara su primera sílaba digital. Pronto, parece que la IA puede devolver el favor.
REFERENCIA
Si quieres conocer otros artículos parecidos a ¿Puede la IA aprender como nosotros? puedes visitar la categoría SER HUMANO.
Continúa Leyendo